kotlin中inline,noinline,crossinline区别?
- 默认函数中如果没加inline,那就是非内联函数,此时lambda会生成一个新的类,该类是继承自Lambda抽象类,并实现了Function接口,其中invoke方法就是Function接口的方法,invoke中的方法就是lambda代码块的代码。
- 内联函数(加inline关键字)的lambda如果没加noinline或crossinline,默认会把lambda的代码块给平铺到调用处,所以此时如果在lambda中加return的话,会直接不执行外层函数后续代码。如果是非内联函数的话,由于它是生成一个单独的类,不存在平铺代码,所以return是编译不过去的。
- noinline和inline是对立关系,它是将lambda不内联处理,如果你需要对该lambda作为对象来使用的时候,此时需要用到noinline,如果一个内联函数都是noinline的lambda表达式,那么此时as会提示你此处可以去掉inline关键字了,当做普通的高阶函数来处理就行。
- 默认内联函数是能添加return来作为局部返回,由于存在平铺代码的特性,所以它能阻止调用lambda的外层函数的执行,那如果lambda作为间接调用的时候,此时添加return语句会编译失败,因为间接调用(比如匿名内部类或回调)不能阻止外层函数的调用,是为了避免多线程或回调中意外终止外层函数,所以kotlin编译器此时需要你添加crossinline,举个例子就清楚了:
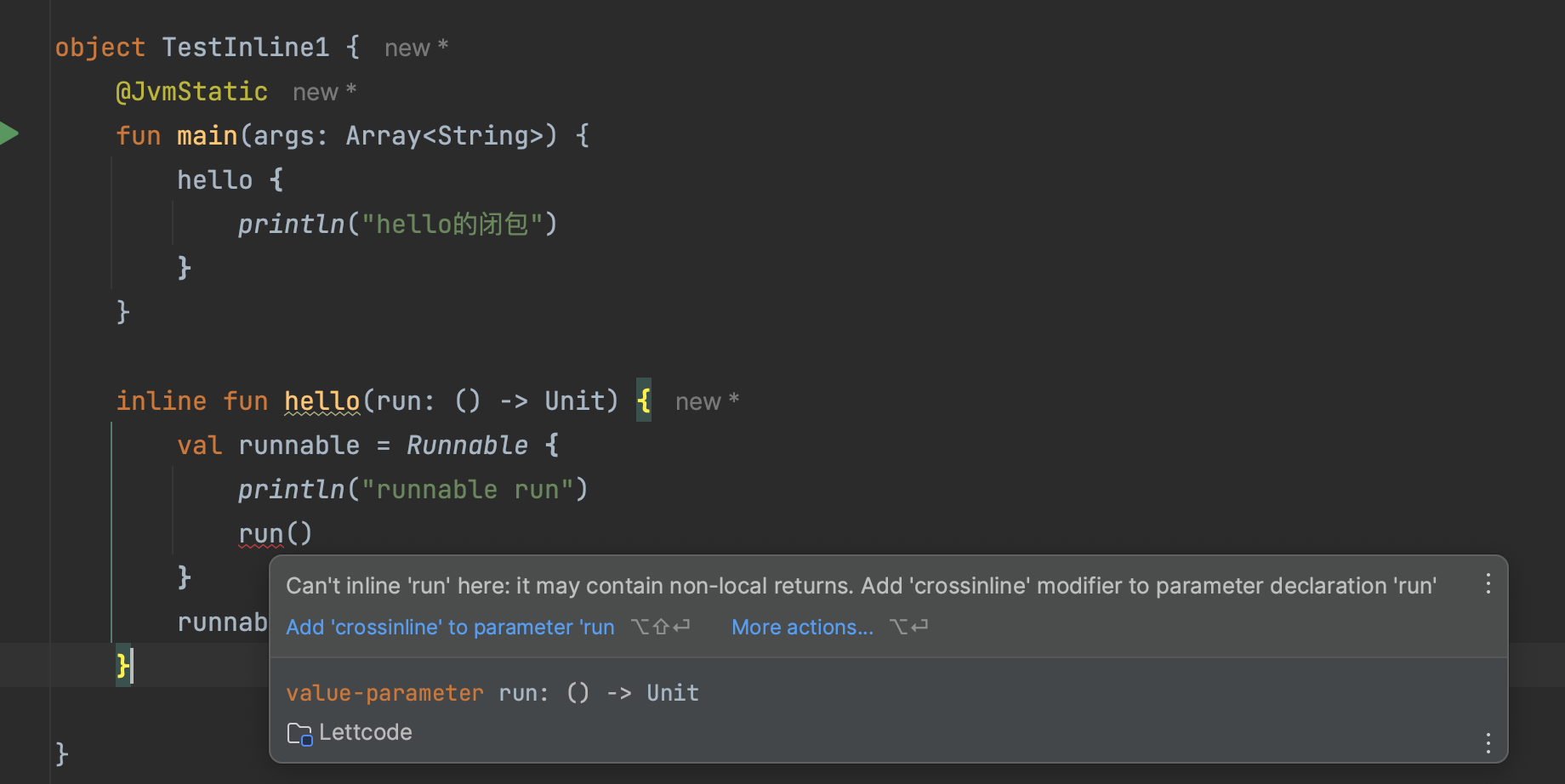
此处的run闭包,它的调用是在runnable接口中的,此时编译器提示 it may contain non-local returns ,意思是此时存在间接调用,在间接调用lambda的时候,不允许在lambda中添加return来阻止外层的外层函数的执行。所以此处通过添加crossinline来阻止lambda中添加return
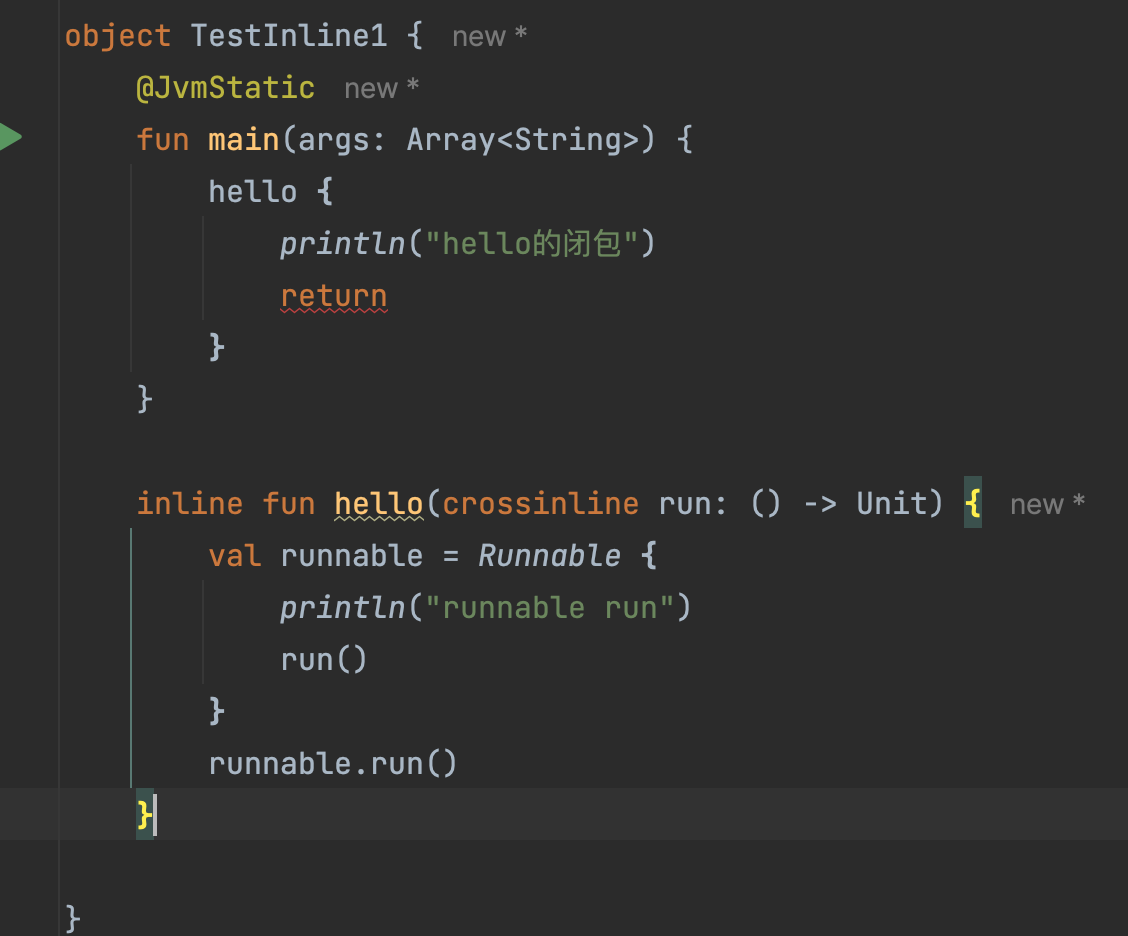
疑惑:crossinline添加后,内联效果还在吗?还是以上面的例子来说明: 假如上面的hello方法我就作为普通的方法,如下:
|
|
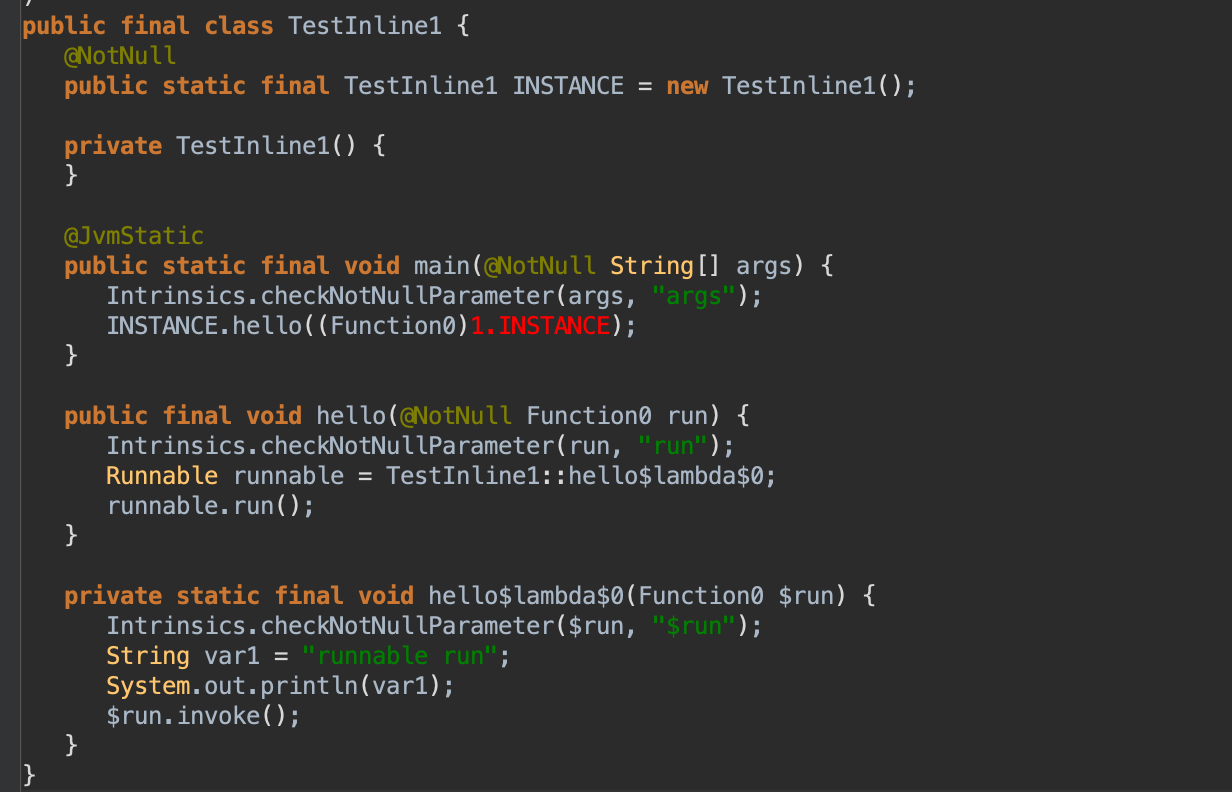
对应的字节码如下:
如果我把它作为内联函数来处理,如下:
|
|
对应的字节码如下:
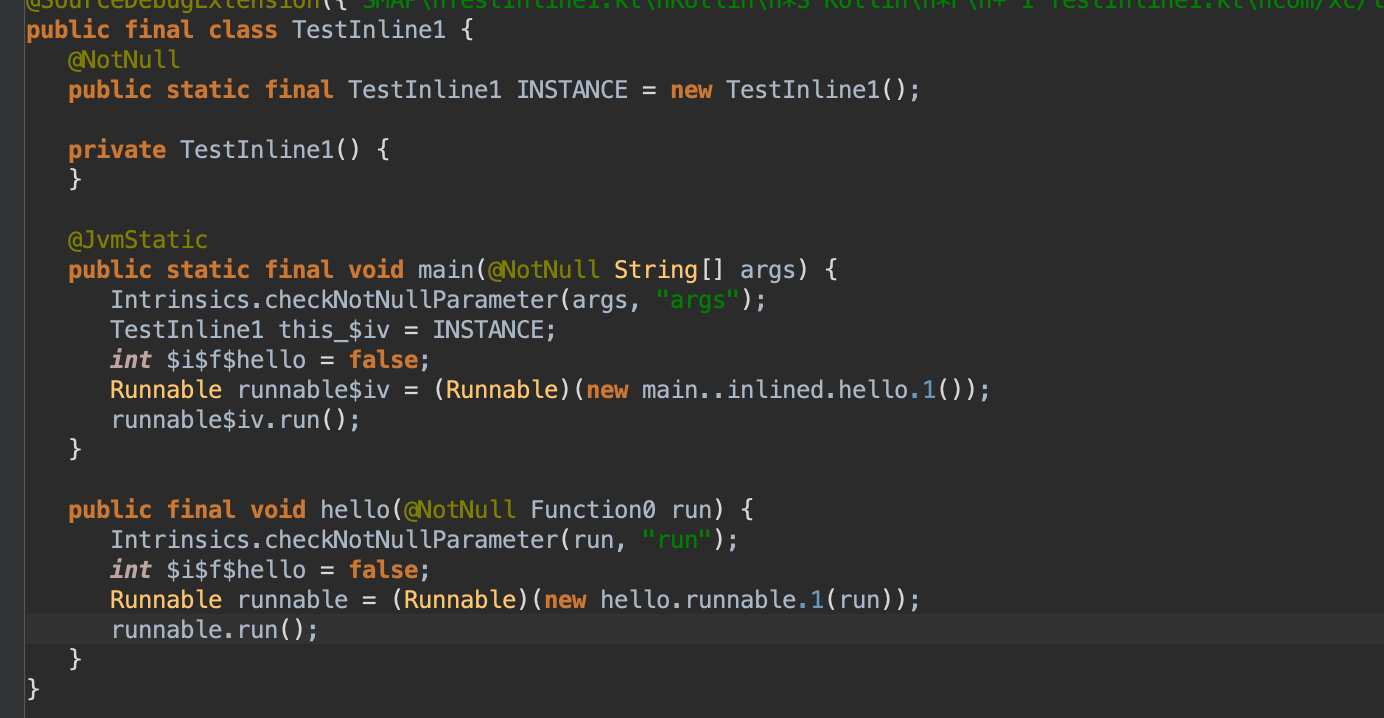

可以看出来crossinline还是有内联效果,闭包直接在runnable中平铺开来了。
相关文档:https://juejin.cn/post/6869954460634841101
java lambda和kotlin lambda区别
- 在java中如果使用匿名内部类的形式,在编译时它是会单独生成一个类,其中类名是「外部类名$index.class」这种形式。如果使用lambda的形式,它不会在编译时单独生成一个类,它是执行了invokedynamic指令,在运行时动态生成lambda的类,其中类名是「外部类名$Lambda$index.class」这种形式。 参考:https://juejin.cn/post/7004642395060961310
- kotlin lambda它是在编译时看是否需要生成单独的类,如果是内联的时候就直接平铺代码,如果是非内联的时候才生成单独的类。
协程是怎么挂起的?怎么恢复的?
- 首先每一个协程代码块都会被编译成SuspendLambda对象,它也是一个Continuation对象,每次在执行到SuspendLambda的resume时候,都会去执行invokeSuspend方法,而该方法里面会去执行子协程,如果子协程返回COROUTINE_SUSPENDED状态的时候,父协程的resume方法会直接return了。当子协程执行完后,会通知父协程,此时父协程的的invokeSuspend方法再次被执行,而此时的状态机会发生变化,如果此时状态恢复后,会执行父协程中的Continuation,也就是父父协程的执行。
协程中的dispather是怎么指定在哪个线程上执行的?
首先dispather它是CoroutineContext(上下文)的一部分,在协程启动过程中,会取CoroutineContext中的CoroutineDispathcer部分。此时会构造一个DispathedContinuation对象,并把前面取到的Dispather传到DispathedContinuation中,此时会将DispathedContinuation扔到线程池中,最终会执行DispathedContinuation的run方法,在run里面会执行到SuspendLambda,也就是协程的代码块,最终会执行它的invokeSuspend方法。所以协程代码块中代码要执行在哪个线程是协程上下文的dispather部分指定的线程。 相关文档:https://www.xiangcman.fun/p/%E5%8D%8F%E7%A8%8B%E5%A6%82%E4%BD%95%E5%88%87%E6%8D%A2%E7%BA%BF%E7%A8%8B/
LinkedList特性
LinkedList继承自Deque,它是一个双端队列,允许在队列的两端插入和删除元素。可以作为栈(LIFO)或队列(FIFO)使用。基于链表(双向链表)实现,可以高效地插入和删除元素。
LinkedHashMap特性
LinkedHashMap继承自HashMap,它比HashMap多了一条双向链表来记录元素的插入顺序或访问顺序。特性如下:
-
维护顺序:通过
accessOrder参数控制accessOrder = false(默认):按插入顺序排序accessOrder = true:按访问顺序排序(每次get/put都会将元素移到链表末尾)
-
数据结构:
1 2 3 4 5 6 7 8 9 10 11// LinkedHashMap 内部结构 // 继承自 HashMap.Node,多了 before 和 after 两个指针 static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } // 还有一个 head 和 tail 指针维护双向链表 transient LinkedHashMap.Entry<K,V> head; transient LinkedHashMap.Entry<K,V> tail; -
LRU缓存实现:利用
accessOrder = true实现LRU缓存1 2 3 4 5 6 7 8// 创建一个按访问顺序排序的 LinkedHashMap LinkedHashMap<Integer, Integer> lruCache = new LinkedHashMap<>(16, 0.75f, true) { // 重写 removeEldestEntry 方法,当 size 超过阈值时删除最老元素 @Override protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) { return size() > 3; // 超过3个元素时删除最老的 } };删除策略:LinkedHashMap删除的是链表头部的元素(即最老的元素),因为它维护的是插入顺序/访问顺序的双向链表,头部是最久未使用的元素。
-
与HashMap的区别:
- HashMap:不保证顺序,遍历顺序不确定
- LinkedHashMap:保证遍历顺序为插入顺序或访问顺序
-
与GroupedLinkedMap的区别(Glide中的GroupedLinkedMap):
- LinkedHashMap:所有元素共用一条LRU链表,淘汰时全局最久未使用的
- GroupedLinkedMap:按Key分组,每组有独立的LRU链,淘汰时在最近最少使用的组内淘汰
-
适用场景:
- 需要保持插入顺序的场景
- 实现LRU缓存
- 需要按访问顺序遍历元素的场景
LinkedList特性(补充)
- offer:给链表尾部插入元素,返回值表示是否插入成功
- peek:取出头部节点,如果没有则返回null
- poll:取出头部节点,如果没有则返回null,取完后并把头部节点从队列中移除
- remove:移除头部节点,如果没有头部节点则抛异常,有的话,则返回
- push:给链表头部插入元素,没有返回值
- pop:和remove一样的,都是移除头部节点,如果没有头部节点则抛异常,有的话,则返回
如果想实现队列的话,则使用offer和poll这一对方法;如果想实现栈的话,可以通过offerLast和pollLast来实现,或者通过offerFirst和pollFirst来实现。
ArrayDeque特性
它也是继承自Deque,和LinkedList的特性一样的,只不过ArrayDeque是通过数组实现的双端队列,内部用一个数组来放所有的节点,并且有两个int值用来存放头结点和尾结点的索引。并且ArrayDeque内部的默认节点容量是16个,也可以初始化容量大小。
区别:如果频繁要插入和删除操作,那么使用LinkedList,如果是查询情况比较多,可以优先使用ArrayDeque。
Pools. Pool
|
|
很明显这是一个对象池,SimplePool继承自Pool,并且可以指定对象池的大小。每次要回收的时候调用release,只有当前size小于对象池最大容量的时候才能回收,每次通过acquire来进行获取对象池中的元素。 其中在recyclerview动画篇章中,分析到InfoRecord对象中会使用Pools. SimplePool,InfoRecord存储的是ViewHolder在pre-layout阶段的坐标信息和post-layout阶段的坐标信息,以及ViewHolder的flag信息。因为ViewHolder的这些信息在动画处理过程中会频繁使用,所以此处使用了对象池来管理。
java中类加载机制
- 首先通过class的name查看有没有加载过,如果没有加载过,看自己的父类加载器是否存在,如果存在,则通过父类加载的loadClass去加载,如果不存在则说明当前类加载器是BootstrapClassLoader加载器,则通过BootstrapClassLoader去加载,如果还没有找到则通过自己的findClass去加载。整体过程理解为先让父类加载器去加载class,如果找不到则自己去加载。
- 类加载器分类:
- BootstrapClassLoader:最顶层的类加载器,它用来加载JAVA_HOME/jre/lib/rt.jar中的类
- ExtClassLoader:扩展类加载器,它用来加载JAVA_HOME/jre/lib/ext目录下的所有jar中的类,它的父加载器是BootstrapClassLoader,继承自URLClassLoader
- AppClassLoader:应用类加载器,它用来加载应用的类,也就是ClassPath,它的父加载器是ExtClassLoader,继承自URLClassLoader
- 自定义ClassLoader:用户实现,任意路径(如网络、文件),可以通过继承自ClassLoader或者是URLClassLoader
- 类加载器采用双亲委托模式来加载class,主要是为了系统的class的安全,优先使用系统的class来加载。
- 双清委托模式的核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0) sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }
android中类加载机制
- android类加载机制也是按照双亲委托模型,但是可以通过自定义类加载器绕过双亲委派,实现类的隔离或复用
- 类加载器分类:
-
BootClassLoader:系统类加载器,加载框架层的核心类(如 android.、java. 等系统类)
-
PathClassLoader:应用类加载器,加载已安装 APK 中的类(即应用自身的类和 classes.dex),它的父类加载器是BootClassLoader,继承自BaseDexClassLoader,用于加载 /data/app/
/base.apk 中的代码,无法加载外部存储的dex、jar文件 -
DexClassLoader:动态加载器,动态加载外部存储的 DEX/JAR 文件或 APK(如插件化、热修复场景),父加载器通常是PathClassLoader,也是继承自BaseDexClassLoader
-
上面提到android类加载也是通过双亲委托模式来加载类,但是安卓加载类是通过解析dex文件来加载的,所以对于PathClassLoader和DexClassLoader都是通过dex来加载class的,对于BootClassLoader,它仍然通过加载系统核心的DEX文件来实现类的加载,只不过这个过程是由虚拟机在底层直接处理的,不需要通过BaseDexClassLoader的DexPathList和DexFile机制。这种设计可能是为了优化系统启动速度和核心类的访问效率。
-
BaseDexClassLoader完成了整个dex转换成class的过程,首先理解几个概念,
DexPathList,DexFile,Element:- DexPathList:被BaseDexClassLoader持有
- Element:被DexPathList持有,内部持有一个Element的数组
- DexFile:被Element持有
- DexPathList通过传入的dexPath,然后通过
;或:进行split,得到List:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54//DexPathList.splitPaths private static List<File> splitPaths(String searchPath, boolean directoriesOnly) { List<File> result = new ArrayList<>(); if (searchPath != null) { for (String path : searchPath.split(File.pathSeparator)) { //省略代码 result.add(new File(path)); } } return result; } //DexPathList.makeDexElements private static Element[] makeDexElements(List<File> files, File optimizedDirectory, List<IOException> suppressedExceptions, ClassLoader loader) { Element[] elements = new Element[files.size()]; int elementsPos = 0; for (File file : files) { if (file.isDirectory()) { elements[elementsPos++] = new Element(file); } else if (file.isFile()) { String name = file.getName(); if (name.endsWith(DEX_SUFFIX)) { DexFile dex = loadDexFile(file, optimizedDirectory, loader, elements); elements[elementsPos++] = new Element(dex, null); } else { DexFile dex = loadDexFile(file, optimizedDirectory, loader, elements); if (dex == null) { elements[elementsPos++] = new Element(file); } else { elements[elementsPos++] = new Element(dex, file); } } } else { System.logW("ClassLoader referenced unknown path: " + file); } } if (elementsPos != elements.length) { elements = Arrays.copyOf(elements, elementsPos); } return elements; } //DexPathList.loadDexFile private static DexFile loadDexFile(File file, File optimizedDirectory, ClassLoader loader,Element[] elements) throws IOException { if (optimizedDirectory == null) { return new DexFile(file, loader, elements); } else { String optimizedPath = optimizedPathFor(file, optimizedDirectory); return DexFile.loadDex(file.getPath(), optimizedPath, 0, loader, elements); } }从上面可以看出来,DexPathList里面会先split出dexPath,然后通过路径生成optimizedPath的路径,通过该路径生成DexFile对象,它就是表示一个dex文件。然后把DexFile塞入到Element数组中,最后该Element数组关联到BaseDexClassLoader中。
- 接着看下如果通过dex加载到class,该处理是在BaseDexClassLoader中的findClass:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58//BaseDexClassLoader.findClass protected Class<?> findClass(String name) throws ClassNotFoundException { List<Throwable> suppressedExceptions = new ArrayList<Throwable>(); Class c = pathList.findClass(name, suppressedExceptions); if (c == null) { ClassNotFoundException cnfe = new ClassNotFoundException( "Didn't find class \"" + name + "\" on path: " + pathList); for (Throwable t : suppressedExceptions) { cnfe.addSuppressed(t); } throw cnfe; } return c; } //DexPathList.findClass public Class<?> findClass(String name, List<Throwable> suppressed) { for (Element element : dexElements) { Class<?> clazz = element.findClass(name, definingContext, suppressed); if (clazz != null) { return clazz; } } if (dexElementsSuppressedExceptions != null) { suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions)); } return null; } //Element.findClass public Class<?> findClass(String name, ClassLoader definingContext, List<Throwable> suppressed) { return dexFile != null ? dexFile.loadClassBinaryName(name, definingContext, suppressed) : null; } //DexFile.loadClassBinaryName public Class loadClassBinaryName(String name, ClassLoader loader, List<Throwable> suppressed) { return defineClass(name, loader, mCookie, this, suppressed); } //DexFile.defineClass private static Class defineClass(String name, ClassLoader loader, Object cookie, DexFile dexFile, List<Throwable> suppressed) { Class result = null; try { result = defineClassNative(name, loader, cookie, dexFile); } catch (NoClassDefFoundError e) { if (suppressed != null) { suppressed.add(e); } } catch (ClassNotFoundException e) { if (suppressed != null) { suppressed.add(e); } } return result; } //DexFile中的native方法 private static native Class defineClassNative(String name, ClassLoader loader, Object cookie,DexFile dexFile) throws ClassNotFoundException, NoClassDefFoundError;从上面可以看到BaseDexClassLoader最终是通过DexPathList->Element->DexFile->native来加载到class
-
android中Choreographer工作内容(android 29)
- 当某个view发起绘制(requestLayout或invalidate)的时候,会调用到ViewRootImpl的scheduleTraversals,该方法里面会给主线程的looper中的消息队列插入了一条消息屏障,接着给Choreographer插入了一条CALLBACK_TRAVERSAL类型的callback:
|
|
- 最终会走到Choreographer的scheduleFrameLocked,默认会走USE_VSYNC,并且默认该线程的looper是主线程的looper,走到如下逻辑,会走到scheduleVsyncLocked,最终会走到DisplayEventReceiver的native方法nativeScheduleVsync,表示监听底层的vsync信号,当vsync信号来的时候会回调onVsync方法,该方法会给主线程发送一条异步消息到消息队列中:
|
|
- 可以看到onVsync中将自己(FrameDisplayEventReceiver)发送到任务队列中,并且执行时间是timestampNanos,说明该任务是要等到vsync信号指定的时间才会执行,它是一个runnable对象,到了执行该任务的时候会执行它的run方法,run方法会执行doFrame,任务队列是执行完上一个任务才会执行下一个任务,所以如果前面的任务一直阻塞着,doFrame其实不会在timestampNanos时间到了的时候,会立马执行的,看下doFrame处理逻辑:
|
|
doFrame主要是先看当前时间和期望的时间进行比较,得到延迟时间,如果该时间大于一帧所需要的时间(60hz刷新率的设备,那么一帧的时间是1000/60=16ms),并且该时间大于30帧的时间时候给出提示,这个时间跟view绘制的anr时间差不多。如果期望的时间比上一帧的时间还小,则说明上一帧还没结束,所以当前帧不处理,直接监听下一个vsync信号。接着就是处理各种callback(input、animation、traversal、commit)。而开头view发起绘制的时候,会插入一条traversal类型的callback,所以会执行到view的绘制流程。
- 当view发起绘制的时候,不会立马执行,而是先给Choreographer插入一条traversal类型的callback,同时让Choreographer监听下一个vsync信号的到来,当vsync信号来的时候,会给主线程的消息队列发送一条异步消息,当处理该消息的时候校验是否有掉帧处理,如果有掉30帧的时候,会给出提示,最后处理各种类型的callback。
vsync信号的作用
- VSync(垂直同步)在安卓屏幕刷新中的作用主要是协调屏幕刷新与图像渲染,避免画面撕裂并提升显示流畅度。具体作用如下:
- 防止画面撕裂
- 当屏幕刷新与图像渲染不同步时,可能出现画面撕裂。VSync通过同步两者的频率,确保屏幕在完整刷新一帧后再显示下一帧,从而避免这一问题。
- 提升流畅度
- VSync确保帧率与屏幕刷新率一致,减少帧率波动,使动画和滚动更加平滑。
- 优化性能
- VSync通过控制渲染节奏,避免GPU过度渲染,减少资源浪费,提升系统效率。
- 双缓冲与三缓冲
- VSync常与双缓冲或三缓冲结合使用。双缓冲通过交替使用前后缓冲区减少等待时间,而三缓冲进一步减少卡顿,提升性能。
- 减少延迟
- 虽然VSync可能增加少量延迟,但通过合理使用双缓冲或三缓冲,可以在保证流畅度的同时尽量降低延迟。
- 总结来说,VSync通过同步屏幕刷新与图像渲染,防止画面撕裂、提升流畅度、优化性能,并减少延迟。
- 防止画面撕裂
消息队列中的消息屏障
- 消息屏障主要是不处理屏障后面的同步消息,优先处理异步消息,实现原理是消息屏障本身是一个没有持有handler的消息,在获取消息的时候,如果发现队列头部是一个消息屏障,则不获取后面的同步消息,只获取后面的异步消息,一般作用于优先级比较高的场景,比如view的绘制流程。当处理完异步消息后,需要移除掉该消息屏障。
android中异常处理
首先理解下java中线程异常机制,如果线程中发生异常了,没有进行try-catch默认会抛给 defaultUncaughtExceptionHandler 的uncaughtException,而android中启动进程后会在RuntimeInit的commonInit方法中给主线程设置上defaultUncaughtExceptionHandler,对应的是KillApplicationHandler,在它的uncaughtException方法中先收集日志,然后kill掉进程。如果有设置线程的uncaughtExceptionHandler,那么此时java异常机制是就不走defaultUncaughtExceptionHandler了,所以不会走KillApplicationHandler,如果没有设置uncaughtExceptionHandler,而通过Thread.uncaughtExceptionHandler.uncaughtException(Exception)的时候,其实是先获取到线程的ThreadGroup,而在ThreadGroup中的uncaughtException中先看parent有没有,如果没有则也是回调到defaultUncaughtExceptionHandler中。
关于多张bitmap转成webp的原理
首先得理解webp是基于VP8/VP8L/VP9视频编码技术,支持有损压缩、无损压缩、透明度和动画。其内部格式基于RIFF(Resource Interchange File Format)文件结构,类似于WAV或AVI的容器格式。webp文件以RIFF头部开始,整体结构如下:
|
|
- RIFF:固定 4 字节标识符。
- FileSize:4 字节,表示文件总大小(包括 RIFF 头部和 WEBP 标签)。
- WEBP:固定 4 字节标识符,表明文件类型。
其中RIFF、FileSize、WEBP这三个归为header部分,chunks归为块部分。其中块可以分为如下部分:
- VP8/VP8L/VP9 图像数据块:
- VP8:用于有损压缩图像(类似 JPEG),块标识符为 VP8 (注意末尾空格)。
- VP8L:用于无损压缩图像(类似 PNG),块标识符为 VP8L。
- VP9:用于更高效的压缩(较少见),块标识符为 VP9 。
- VP8X(扩展元数据块):
- 标识符为 VP8X,用于存储扩展信息(如宽度、高度、动画标志、Alpha 通道等)。
- 必须出现在其他块之前(除 RIFF 和 WEBP 外)。
- 包含以下标志位:
- 动画(Animation)
- Alpha 通道(Alpha)
- EXIF 元数据
- XMP 元数据
- ICC 颜色配置文件
- ANIM(动画控制块):
- 标识符为 ANIM,仅用于动画 WebP。
- 包含背景颜色和循环次数。
- ANMF(动画帧块):
- 标识符为 ANMF,每个动画帧对应一个 ANMF 块。
- 包含帧的位置、时间延迟、宽度、高度等。 了解文件结构后,下面来介绍如何将多个bitmap生成webp:
- VP8/VP8L/VP9 图像数据块:
- 首先将bitmap压缩成webp格式的图片,按照50的压缩比,放到字节输入流中
- 读取webp的header部分
- 读取RIFF部分
- 读取文件大小
- 读取WEBP部分
- 读取第一个带有playload的chunk块
- 由于前面指定了bitmap转webp的时候是有损,因此读取chunk的时候直接去读WP8块,接着读取它的payload信息,playload大小就是chunk大小,4字节。
- 读取完后,接着就是写入到输出流中,判断如果是第一个bitmap,则创建header部分,其中header也是按照RIFF、FileSize、WEBP三个区域写回,接着写入VP8X数据块,标明宽高、动画、通道、元数据等信息。接着创建ANIM动画控制块,标明背景颜色和循环次数。最后创建每一个bitmap对应的ANMF动画帧块,将指定每一帧的的尺寸、时长playload数据。
kotlin中 == 和 === 区别
kotlin中的==:如果是对象类型,比较的是equals方法;如果是基本类型,比较的是值。 kotlin中的===:如果是对象类型,比较的是内存地址,指向的是不是同一个对象;如果是基本类型。比较的还是值。
kotlin中lazy的原理
Lazy本身是一个接口,会提供一个value属性和isInitialized的方法,注意了在kotlin接口中提供属性,其实对应java中的get**方法,平时写的by lazy{},去定义一个属性的时候,其实它是一种属性委托的写法,但是lazy它是只读的委托模式,所以在定义属性的时候必须用val来修饰变量。当我们去读取lazy的变量的时候,实际是调用了前面定义的value属性,对应java代码其实是getValue方法,当首次去获取属性的时候,发现_value为空,所以会通过闭包去获取,获取到后会将返回值给到_value,下次再调用getValue的时候,直接返回该_value。
|
|
- 第一个参数lock是可以传入对象锁
- 第二个参数是传进来的闭包,是非空
- 返回值:实际是一个SynchronizedLazyImpl对象:
|
|
综上来看,lazy默认是线程安全的,默认使用的对象锁是当前lazy对象,也可以自己传入锁对象。使用Volatile来保证对象的可见性,通过synchronized保证创建对象是原子操作。
kotlin委托模式
-
属性委托:允许你把属性的getter、setter逻辑委托给一个独立的对象来管理
- 通过「var 属性 by 委托类」的形式定义一个属性委托的过程,当使用var的时候,说明该属性能可读和可写,在属性写的时候实际编译器会去调委托类的setValue方法,当属性读的时候实际编译器会去调委托类的getValue方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18class Delegate { operator fun getValue(thisRef: Any?, property: KProperty<*>): String { return "属性 ${property.name} 被代理了" } operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) { println("属性 ${property.name} 赋值为 $value") } } class Example { var message: String by Delegate() } fun main() { val e = Example() println(e.message) // 访问时调用 getValue() e.message = "Hello" // 赋值时调用 setValue() }实际对应的字节码:
1 2 3 4 5 6 7class Example { private val message$delegate = Delegate() // 委托对象变为一个私有属性 var message: String get() = message$delegate.getValue(this, ::message) set(value) = message$delegate.setValue(this, ::message, value) }- by Delegate() 其实是 Kotlin 编译器生成的 get() 和 set() 方法。
- getValue() 和 setValue() 由 Delegate 这个委托对象实现。
-
类委托:允许一个类 将实现某个接口的功能委托给另一个对象,减少代码重复。
- by 关键字 可以让 Kotlin 自动生成委托方法,避免手写重复代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17interface Printer { fun printMessage() } class RealPrinter : Printer { override fun printMessage() { println("RealPrinter: 打印内容") } } class ProxyPrinter(printer: Printer) : Printer by printer fun main() { val realPrinter = RealPrinter() val proxy = ProxyPrinter(realPrinter) proxy.printMessage() // 调用的是 realPrinter 的方法 }上面的ProxyPrinter被编译器编译为如下:
1 2 3 4 5 6 7class ProxyPrinter(printer: Printer) : Printer { private val printerDelegate: Printer = printer override fun printMessage() { printerDelegate.printMessage() } }- by printer 让 ProxyPrinter 自动实现 Printer 接口的方法,而不需要手动实现。
- 编译器在字节码层面会自动插入代理方法,提高代码简洁性。
为什么reified必须和inline一起使用?
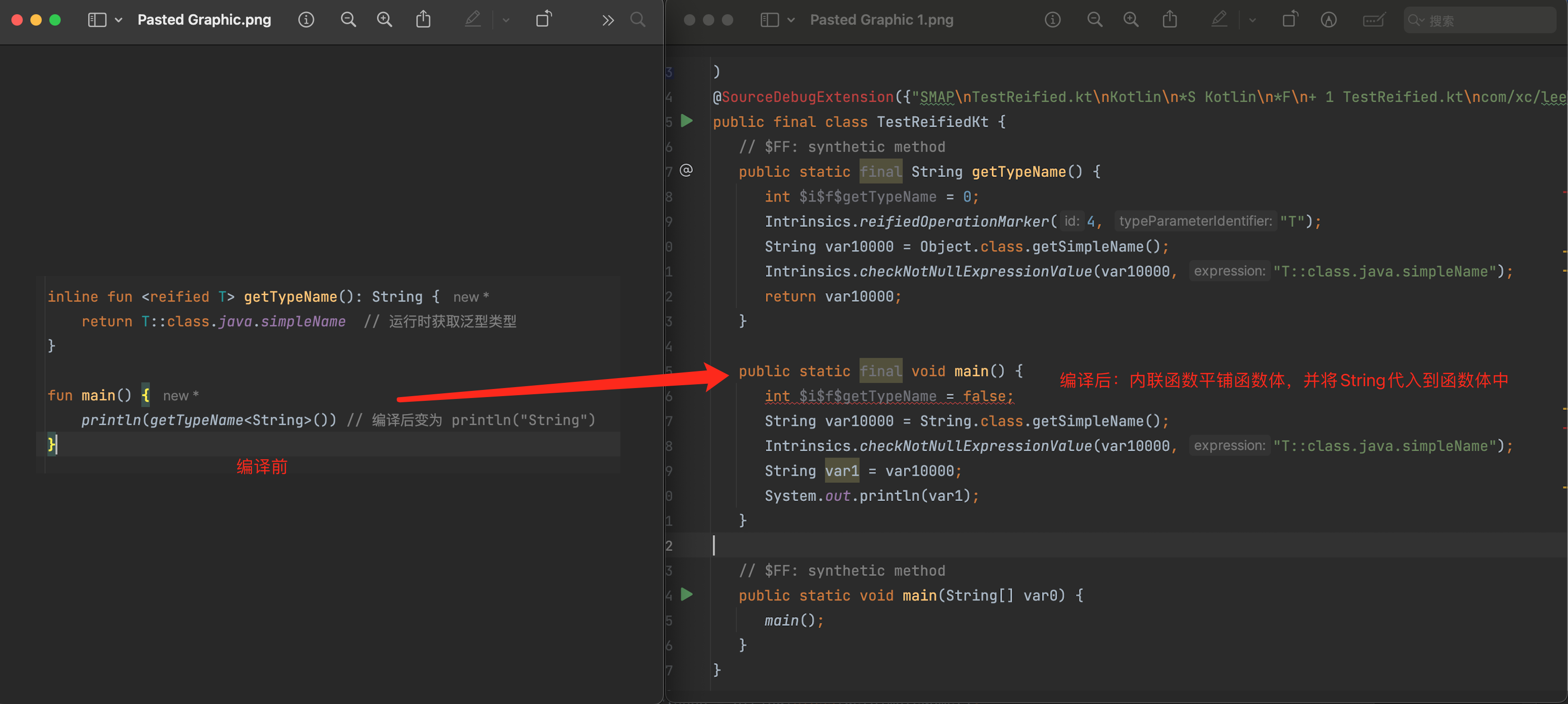
reified关键字是用来修饰泛型,而泛型在编译后会被擦除掉,所以如果要在运行时获取到泛型的类型,就得用reified关键字,而inline的作用是修饰方法内联,之前讲内联函数的特点是将函数体平铺到调用处。那它两有什么联系呢?先来看一个例子:

此处提示我,使用reified关键字来修饰泛型,因为泛型在编译后,会被擦除掉,所以是获取不到它的类型,只有添加reified才能保证它的类型存在。那添加完reified后提示为什么还要添加inline呢? 这是因为只有内联函数将函数体进行平铺,然后将泛型通过「真类型」代入到函数体中,看下编译后的代码:
关于viewModel的一些思考
- 创建:默认都是通过ViewModelProvider的get方法获取到viewModel,里面通过factory(工厂方法模式)的create来创建viewModel,创建完之后会把viewModel保存到ViewModelStore中。ViewModelStore实际是用一个hashMap来存储viewModel,key是viewModel的class name拼上前缀,value就是当前viewModel。android中默认的factory是ViewModelProvider. AndroidViewModelFactory,在它的create方法里面通过前面传进来的viewModel的class反射创建viewModel。
- 存储:像平时写的activity都是继承自
ComponentActivity,它是实现了ViewModelStoreOwner接口,该接口需要持有一个ViewModelStore,ViewModelStore是在ensureViewModelStore方法中创建的:
|
|
getLastNonConfigurationInstance()方法是获取Activity中的mLastNonConfigurationInstances属性的activity属性,结构如下:
|
|
第一次打开activity的时候mLastNonConfigurationInstances属性是空的,因此在ensureViewModelStore中是直接创建了ViewModelStore。那什么时候mLastNonConfigurationInstances不为空呢?我们注意到mLastNonConfigurationInstances是在activity的attach中赋值的,它的上级来源是ActivityClientRecord中的lastNonConfigurationInstances属性,那什么时候给ActivityClientRecord的lastNonConfigurationInstances属性赋值呢?这个可以在aosp中的 frameworks/base/core/java/android/app/Activity.java 类中的performDestroyActivity方法中找到:
|
|
而activity的retainNonConfigurationInstances方法中会组装NonConfigurationInstances中的activity属性,是通过onRetainNonConfigurationInstance方法来收集的:
|
|
onRetainNonConfigurationInstance方法的调用是在 ComponentActivity 中实现了:
|
|
可以看到最终viewModelStore通过ComponentActivity中的NonConfigurationInstances存储起来了,最终被ActivityClientRecord持有。当横竖屏切换的时候会触发ActivityThread的handleRelaunchActivity,在该方法里面会先将activity的lastNonConfigurationInstances保存到ActivityClientRecord,等到创建activity的时候会把lastNonConfigurationInstances给到activity,所以viewmodelStore此时拿到的还是之前的。
- fragment中的viewModel是怎么存储的?
- fragment也是实现了viewModelOwner接口,所以它也有自己的viewModelStore,它的viewModelStore是通过FragmentManagerViewModel来管理的,FragmentManagerViewModel的创建是看当前fragment有没有parentFragment,如果有,则通过parentFragment的fragmentManager的getChildNonConfig方法来获取。如果parent为空,则通过activity的viewModelStore来创建。所以fragment的viewModelStore存储也是依赖于activity,因为最终该FragmentManagerViewModel是通过activity的viewModelStore来存储的。
- ViewModel传参问题
- 使用自定义ViewModelProvider.Factory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38// ViewModel 需要参数 class UserDetailViewModel( private val userId: String? ) : ViewModel() { // ... init { Log.d("UserDetailViewModel", "userId:${userId}") } fun test() {} } // Activity 中使用 class UserDetailActivity : AppCompatActivity() { private val userId = "张三" // ✅ 使用 extrasProducer 传递参数 private val viewModel: UserDetailViewModel by viewModels( factoryProducer = { object : ViewModelProvider.Factory { override fun <T : ViewModel> create( modelClass: Class<T> ): T { return UserDetailViewModel(userId) as T } } } ) override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) viewModel.test() } companion object { val USER_ID_KEY = object : CreationExtras.Key<String> {} } } - 使用自定义ViewModelProvider.Factory+CreationExtras给ViewModel传值
- 在activity的viewmodels扩展函数中传入extrasProducer和factoryProducer,他两都是闭包,extrasProducer参数指定闭包中返回的是MutableCreationExtras,factoryProducer参数指定的是一个ViewModelProvider.Factory的匿名类,重写create方法,返回需要的ViewModel:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48// ViewModel 需要参数 class UserDetailViewModel( private val userId: String? ) : ViewModel() { // ... init { Log.d("UserDetailViewModel", "userId:${userId}") } fun test() {} } // Activity 中使用 class UserDetailActivity : AppCompatActivity() { private val userId = "张三" // ✅ 使用 extrasProducer 传递参数 private val viewModel: UserDetailViewModel by viewModels( extrasProducer = { MutableCreationExtras().apply { set(USER_ID_KEY, userId) } //MutableCreationExtras可以通过传入其它的CreationExtras,比如此处传入了defaultViewModelCreationExtras,然后做一个拼接 //MutableCreationExtras(defaultViewModelCreationExtras).apply { // set(USER_ID_KEY, userId) //} }, factoryProducer = { object : ViewModelProvider.Factory { override fun <T : ViewModel> create( modelClass: Class<T>, extras: CreationExtras ): T { return UserDetailViewModel(extras.get(USER_ID_KEY)) as T } } } ) override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) viewModel.test() } companion object { val USER_ID_KEY = object : CreationExtras.Key<String> {} } } - 通过SavedStateHandle存储ViewModel中的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26class MyViewModel( private val savedStateHandle: SavedStateHandle ) : ViewModel() { var userName: String? get() = savedStateHandle.get<String>("user_name") set(value) = savedStateHandle.set("user_name", value) } // Activity 中使用 class UserDetailActivity : ComponentActivity() { // ✅ 默认会自动提供 SavedStateHandle private val viewModel: MyViewModel by viewModels() override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) viewModel.userName = "张三" val userName = viewModel.userName Log.d("UserDetailActivity", "onCreate:${userName}") } // 或者显式指定(效果相同) //private val viewModel: MyViewModel by viewModels( // extrasProducer = { // defaultViewModelCreationExtras // 包含 SavedStateHandle // } //) }- SavedStateHandle作为viewModel中存储值的介质,它能够保存变量,它在进程被杀后,还能恢复里面的内容,它相当于viewModel+onSaveInstanceState的结合体。
- viewModel直接取Intent中存储的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27class UserDetailViewModel( private val savedStateHandle: SavedStateHandle ) : ViewModel() { // ✅ 从 Intent 获取参数(如果存在) private val userId: String get() = savedStateHandle.get<String>("user_id") ?: throw IllegalStateException("user_id is required") init { Log.d("UserDetailViewModel", "userId:$userId") // 如果 Intent 中有 user_id,会自动保存到 savedStateHandle // 可以通过 get() 获取 } fun test(){} } // Activity 中传递参数 class UserDetailActivity : ComponentActivity() { private val viewModel: UserDetailViewModel by viewModels() override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) viewModel.test() } }- 假如其他的页面跳转到UserDetailActivity时候,会将intent参数传给UserDetailActivity,此时在UserDetailViewModel中能通过SavedStateHandle获取到Intent中的参数。
- 使用自定义ViewModelProvider.Factory
LiveData的一些思考
- liveData是基于监听lifecycle生命周期的数据驱动框架,在lifecycle为STARTED才会触发触发数据驱动,并且在lifecycle为DESTROYED的时候自动解绑observer。
- 比如我在lifecycle的CREATED状态给livedata灌数据,等到lifecycle状态为STARTED的时候就会给livedata的observer给发送数据。
- 当提前给livedata灌输数据的时候,但是此时还没添加observer,等到添加observer的时候,会自动把数据分发到observer中了。这个就是数据倒灌。主要是因为给livedata发送数据的时候,livedata中的版本号会+1,但是新添加的observer此时的版本号还是-1,所以在注册的时候,会把数据分发给observer。通常数据倒灌的解决方案是:
- 每次在添加observer的时候,反射将livedata中的版本号给置为0
- 重写livedata,然后添加一个已经注册的标记(AtomicBoolean),第一次调用observe的时候才会给该标记置为非空。此时在发送数据的时候判断如果该标记不为空,才会置为true,在observe的地方通过包装一个observer,只有该标记置为true了,才会给到目标observer传递数据。(这种方案只适合添加单observer的场景,如果多observer就不适合了)
- 继承livedata,用一个map记录observer是否接收过消息,如果接收过了就不能再接收
- livedata中的getVersion方法是包内可见的,因此我们可以新建和livedata同样的包名的类,这样就能访问getVersion方法,然后在observe方法中判断如果version>START_VERSION才会能消费事件
- livedata中setValue是同步方法,是线程不安全的。postValue在一个线程的时候,如果发送数据比较频繁的时候,只会把最后一个数据发送给observer,因为postValue是通过给主线程的消息队列发送数据,然后发送给observer。在多线程情况下虽然设置数据是加了同步块,但是因为还是给主线程的消息队列发送消息来切换线程,导致前面的数据会被后面的数据给覆盖。
glide缓存
- glide缓存分为内存和硬盘两类,其中内存缓存又分为活跃缓存和LRU缓存,硬盘缓存分为解码后按照view尺寸展示的bitmap缓存,另外一部分是原始图片的缓存。
- 活跃缓存:它的结构是一个hashmap,其中key是按照url、尺寸等信息拼成的,value是一个弱引用对象,其中弱引用中放的才是图片缓存对象。
- LRU缓存:它底层是一个LRU策略的缓存,key也是和上面活跃缓存用的是同一个。value存的是解码后的图片缓存。
- 解码后的硬盘缓存:也是使用的LRU策略的缓存,其中key是按照指定尺寸来构建的,然后从DiskLruCache中获取缓存。
- 原始图片的硬盘缓存:也是使用的LRU策略的缓存,其中key不是通过指定尺寸来构建的,然后也是从DiskLruCache中获取缓存。
- 缓存获取步骤:
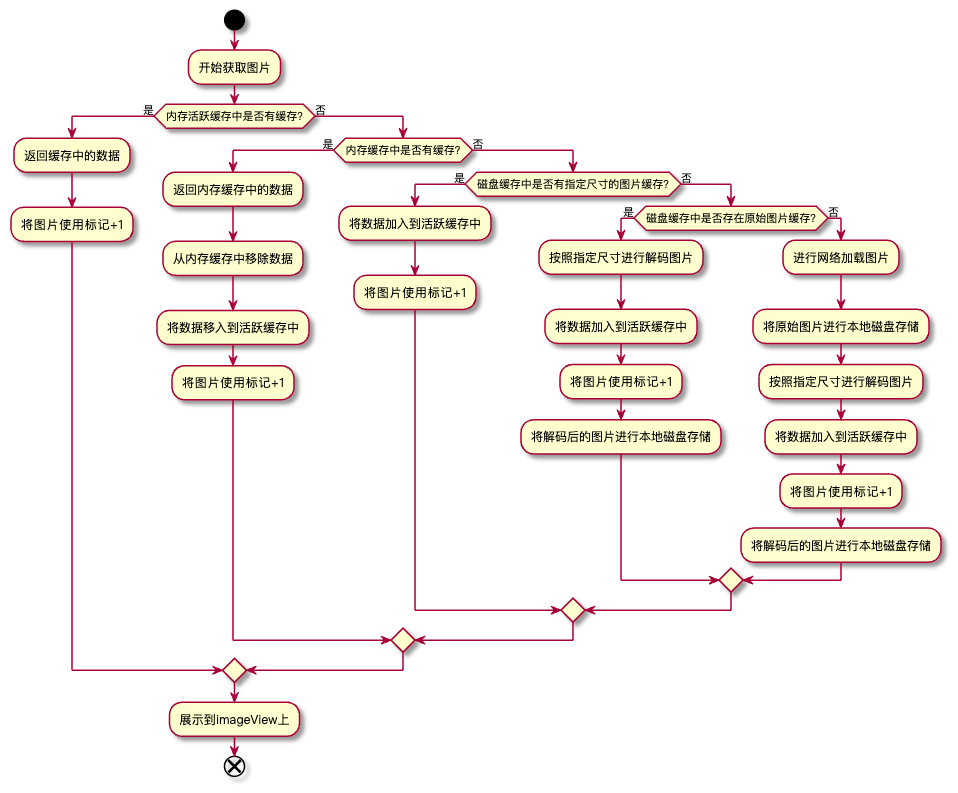
- LRU的内存缓存是在什么存储的?
- 从上面流程图来看每次从非活跃缓存中获取到图片缓存后,都会放入到活跃缓存中,那什么时候会放到内存的LRU缓存中呢?当view触发onViewDetachedFromWindow的时候,也就是当前view销毁后,会查看当前view绑定的图片被正在使用标记的次数,如果次数为0了,则将当前图片加入到LRU的内存缓存中。
- glide为什么要设计两层的内存缓存?
- 内存缓存分为活跃的缓存,它是一个map数据结构,value存储的是弱引用包装了缓存数据,另外一层是LRU级别的缓存。活跃数据指的是当前正在使用的资源,比如正在显示的图片,这部分用弱引用来保存,这样当图片不再被使用时,垃圾回收器可以自动回收,避免内存泄漏。而LRU缓存则是最近最少使用的缓存,使用强引用,当内存不足时,会移除最久未使用的资源。
- 如果只有LRU缓存的时候,正在使用的图片可能是长时间没有被访问的图片,而此时如果只有LRU缓存的时候,可能会把正在使用的图片缓存给移除掉了,这样的话,当再使用该图片的时候,会从磁盘中去获取该图片,这样增大了获取图片的时间。如果只有弱引用缓存的时候,此时图片不被使用了,被GC给回收了,那此时也只能从磁盘中获取,增大了获取图片的时间。如果此时有LRU缓存,能在内存中保留一段时间,降低从磁盘中读取的可能。
kotlin中Sequence和普通集合的区别
Sequence原理是持有了原有集合的iterator,在等到调用toList的时候,才会拿到Sequence的iterator进行遍历,然后添加到新的集合中。中间的操作符都会生成一个新的sequence,然后每遍历一个元素都会去执行一次中间操作符的iterator的next方法,然后将结果给到下一个sequence,最后添加到新的集合中。 优点:相较于普通的集合,它是惰性执行中间操作符,并且中间的操作符只是通过iterator进行迭代每一个元素,而普通的集合是每一个操作符会新生成一个集合,导致内存会增高。Sequence的使用场景是中间操作符比较多的情况下进行使用,不会增加新的集合,并且是惰性遍历元素。 比如下面这个操作:
|
|
在调用toList时候,才会执行上面的map和filter方法,并且map和filter遍历元素的时候,是每个元素依次调用到map和filter,中间是通过sequence的iterator进行遍历,不会产生中间的集合。 日志如下:
|
|
再来看下普通集合的操作:
|
|
上面的map和filter是分开执行的,不会等到最后才执行,所以没有惰性,map和filter都会产生新的集合,并且在遍历元素的时候,每一个操作符是先遍历完每一个元素,然后才执行下一个操作符的遍历。 日志如下:
|
|
kotlin中Sequence和集合的Stream区别
Stream是java1.8之后出的语法,和Sequence一样支持流式和惰性的特点,它在遍历元素的时候也是每个元素都会按顺序经过中间的操作符,不像普通的集合那样每个元素必须先执行完一个操作符,然后才进行下一个操作符。但是Stream只能一次性消费,消费完后,就不能再使用该stream。而Sequence可以多次使用。同时Stream的parallelStream方法支持并发处理,遍历元素的时候,不是按照元素会顺序执行每一个操作符,当数据量大的时候可以考虑使用parallelStream。
companion object和object中定义变量
在companion object定义非const变量的时候,会在Companion内部类中提供get方法,在外部类中定义该常量:
|
|
生成的class代码如下:
|
|
如果kotlin代码如下:
|
|
对应class代码如下:
|
|
在有const的时候,不会在Companion内部类中提供get方法。只会在外部类提供公开类型的常量。 如果在object类中定义const变量,如下:
|
|
会生成如下class:
|
|
如果去掉const会生成如下class:
|
|
从上面伴生对象和object类发现伴生对象会生成内部类,并通过饿汉式生成单例。object是在内加载的时候生成单例。
记录一次gradle编译问题
- 问题:在添加某个广告sdk后,发现工程中编译会报错,报错信息如下:
- Caused by: org.jetbrains.kotlin.gradle.tasks. CompilationErrorException: Compilation error. See log for more details
- ‘onNewIntent’ overrides nothing
- 该问题说activity的子类(kotlin类)中出现了onNewIntent方法中的intent参数定义可为空了,就增加了一个广告的sdk后,怎么就提示intent要定义成不为空的呢。既然是广告sdk导致的,那么下面就按照依赖关系把问题找到,执行gradle的命令如下:
|
|
上面命令会找到app依赖的所有module的间接依赖,并输出到文件中,直接看新增的广告sdk的module信息:
|
|
可以看到,在广告sdk中会把activity-ktx的版本从1.7.1升级到1.9.2,继续顺藤摸瓜,发现在1.9.2的版本中 ComponentActivity ,会给onNewIntent方法的intent参数加上了 @Suppress("InvalidNullabilityOverride") 注解,而在1.7.1版本中是加上 @SuppressLint({"UnknownNullness", "MissingNullability"}) 注解。通过Gemini对比两者的区别,最终得出结论:
- @Suppress(“InvalidNullabilityOverride”)
- 如果一个 Java 方法的参数是 String param,Kotlin 编译器可能无法确定它是可空 (String?) 还是非空 (String)。如果你将其重写为 param: String?(可空),但 Kotlin 编译器内部推断它应该是 String(非空),或者反之,就会触发 InvalidNullabilityOverride 警告。
@SuppressLint({"UnknownNullness", "MissingNullability"})- 它是lint中的注解,用于抑制 Lint 工具发出的特定警告或错误。UnknownNullness:当 Lint 工具无法确定某个变量、参数或返回类型的空安全性时(通常是因为它来自没有空安全注解的 Java 代码或第三方库),它会发出此警告,提醒你其空安全性是未知的。MissingNullability:当 Lint 认为某个地方应该有空安全注解(@NonNull 或 @Nullable),但却缺失了时,它会发出此警告。这通常发生在你在编写 Java 代码,但没有为参数或返回类型明确添加空安全注解时。
- 目的: 告诉 Lint 工具:“我已经意识到这里存在空安全注解缺失或未知空安全性的问题,但我有理由不添加注解或接受当前状态,请不要再警告我。”
- 从上面分析可知,而activity中的onNewIntent方法中确实没有任何非空和可空的注解,在1.7.1版本中通过lint注解来告诉lint,这里的intent参数是不可确定的空参数,不需要发出警告。而在1.9.2版本中强制要求子类中必须为非空的,因此当之前的子类是可空的时候,就会出现前面所说的编译问题
- 方案:直接在添加广告sdk的地方,排除掉activity-ktx的依赖:
|
|
kotlin协程中的withTimeoutOrNull作用
场景adb中命令
- 通过包名查看pid
- adb shell pidof 包名
- 返回进程的id,通过该id后面可以做很多事情
- adb shell pidof 包名
- adb shell cat /proc/pid/stat
- 获取App cpu使用时间
- 3541 (进程名) S 906 906 0 0 -1 1077952832 801953 19794 170 1 195874 29787 16 55 10 -10 247 0 76295047 29784014848 99929 18446744073709551615 1 1 0 0 0 0 4612 1 1073775868 0 0 0 17 4 0 0 3 0 0 0 0 0 0 0 0 0 0
- 上面的14-17部分是我们关心的数据
- 195874:utime(进程的用户态时间)
- 29787:stime(进程的内核态时间)
- 16:cutime(子进程的用户态时间)
- 55:cstime(子进程的内核态时间)
- 把这几个加起来就可以得到当前App总CPU使用时间
- 上面的14-17部分是我们关心的数据
- 3541 (进程名) S 906 906 0 0 -1 1077952832 801953 19794 170 1 195874 29787 16 55 10 -10 247 0 76295047 29784014848 99929 18446744073709551615 1 1 0 0 0 0 4612 1 1073775868 0 0 0 17 4 0 0 3 0 0 0 0 0 0 0 0 0 0
- 获取App cpu使用时间
快速查看某个应用的activity栈的情况
- adb shell dumpsys activity activities | grep Hist | grep 包名
阿里云域名如何关联github page
首先来到 云解析DNS/公网权威解析模块 ,然后找到购买的域名,进入到解析设置的tab,选择 添加记录 ,添加两项信息:

Class.isAssignableFrom()
判断当前class是不是参数中class的父类类型或当前类型,比如Drawable.class.isAssignableFrom(BitmapDrawable.class)返回为true。
url转uri
|
|
如果是形如/path1/path2这种形式直接通过toFileUri转化成Uri,如果不是,则通过Uri.parse转化成Uri,并判断Uri的scheme,scheme是什么:
这个资源应该用哪种协议来访问。
比如常见scheme:
| scheme | 含义 |
|---|---|
| http | 通过 HTTP 协议访问资源 |
| https | 通过 HTTPS(加密的 HTTP)协议访问资源 |
| ftp | 使用 FTP 下载/上传文件 |
| file | 本地文件,例如 file:///sdcard/test.txt |
| content | Android 的 ContentProvider,例如 Uri.fromFile 或 content://media |
| data | Data URI,直接把数据编码在 URI 内 |
| mailto | 打开邮箱,例如 mailto:xxx@gmail.com |
Math相关方法
- Math.ceil: 向上取整,比如6.1向上取整得到7
- Math.floor: 向下取整,比如6.7向下取整得到6
- Math.round: 四舍五入计算取整
plantUml中class关系说明
- 继承:A –|> B
- 实现:A ..|> B
- 构成:A –* B,表示A强依赖B,整体与部分不可分离
Car –* Engine
1 2 3class Car { private Engine engine = new Engine(); // Car 死 Engine 必死 } - 聚合:A –o B,弱依赖,整体与部分可独立存在。
|
|
Team –o Player 5. 依赖:A –> B,类在运行时使用另一个类,通常表示局部变量、方法参数。
|
|
OrderService –> OrderValidator
adb快速无线连接
- 设置adb的端口号:
1adb tcpip 5555 - 首先显示wifi的ip地址:
1adb shell ip addr show wlan0 - 连接设备
1adb connect 后面跟ip地址
java中byte转成int
- 首先byte的取值范围是-128到127,它是占用2个字节,它的最大值是
0111 1111,也就是2^7-1 = 127。最小值是1000 0000,最高位为1,也就是负数,所以是-2^7=-128。 - 如果byte的二进制直接得到int的话,会看它的最高位,如果是1的话,则是负数。负数是用补码(取反)+1:
所以为了消除byte表示整数的问题,那么需要先将byte数和0xff进行相与,然后就得到整数:
1 2byte b = (byte) 0xF0;//1111 0000,最高一位是1,所以是负数,负数是用补码(取反)+1,先取反:0000 1111,再加一:0001 0000,得到-16 System.out.println("b = " + b);1 2 3byte b = (byte) 0xF0; int i = b & 0xFF; System.out.println("i = " + i);//240=2^7+2^6+2^5+2^4
java中字节流的处理
- java中字节流主要指BufferedInputStream,它可以通过将FileInputStream作为被装饰对象,然后进行扩展,这也是java中io使用到了装饰者模式。装饰者分为抽象组件和具体组件。装饰器分为抽象装饰器和具体装饰器。其中InputStream是抽象组件,FileInputStream是具体组件。FilterInputStream是抽象装饰器,也就是BufferedInputStream的父类,它也继承自抽象组件InputStream。而BufferedInputStream是具体的装饰器。可以在字节处理上进行扩展。
- BufferedInputStream它是带有一个byte数组的缓冲区,它可以将内容读取到该缓冲区中,然后通过缓冲区获取到文件中的内容。
例子:有个
12345678数字的test.txt文件,想通过BufferedInputStream来读取:
|
|
读取结果:
|
|
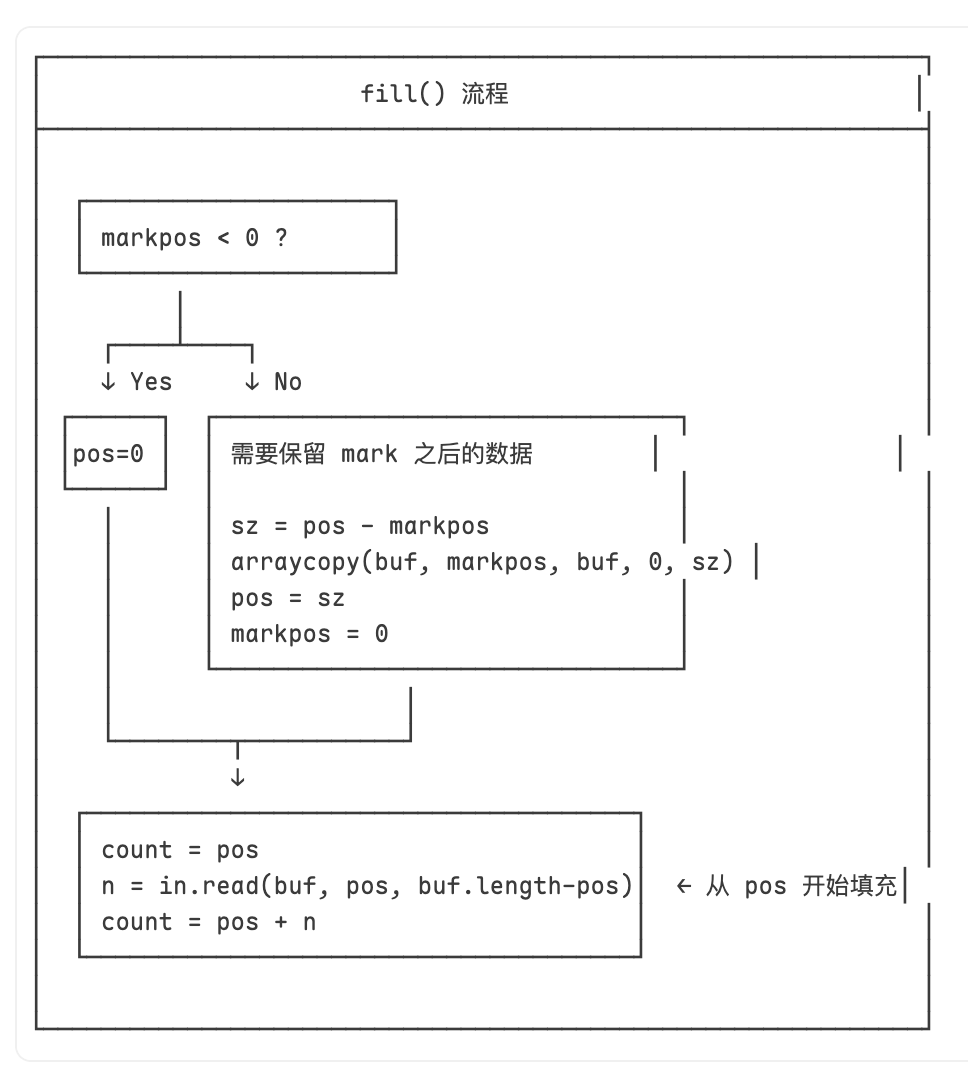
在上面定义了缓冲区的大小为4字节,而文件内容是8字节。当缓冲区内容满的时候,会再次给缓冲区填充内容,而填充内容的时候,底层流会记住fill前的位置,所以当第二次fill时候,会把剩余的4字节数据又读取到缓冲区中。每次fill都会把原来的数据给覆盖掉了,因为在fill中判断markPos是否为0,如果为0。则新位置从0开始。
- BufferedInputStream带有标记功能,通过mark方法来标记当前的位置,当发现有mark时候,fill中会将mark之后位置数据给放到缓冲区的开头位置。而将剩余的空间让给新的数据继续读取。


- BufferedInputStream的回退能力,如果标记后,我们想回到被标记位置,调用reset方法能回到被标记的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21public class TestBufferInputStream1 { public static void main(String[] args) throws IOException { //此处的test.txt文件是8个字节,所以在下面的数据中是8次 BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("./test.txt")); char a = (char)bufferedInputStream.read(); char b = (char)bufferedInputStream.read(); bufferedInputStream.mark(3);//在pos=2,也就是第3个位置做标记,marklimit=3 char e = (char)bufferedInputStream.read(); char f = (char)bufferedInputStream.read(); System.out.println("a = " + a);//1 System.out.println("b = " + b);//2 System.out.println("e = " + e);//3 System.out.println("f = " + f);//4 bufferedInputStream.reset();//reset方法后会将读取位置回退到标记位置,也就是第三个位置 char c = (char)bufferedInputStream.read(); char d = (char)bufferedInputStream.read(); System.out.println("c = " + c);//读取到3 System.out.println("d = " + d);//读取到4 } }
RandomAccessFile
- RandomAccessFile能按照字节位置进行移动,然后在指定位置能写入数据,但是它写入数据是覆盖掉原来位置的数据,比如下面例子的处理:
1 2 3 4 5 6 7 8 9 10 11 12public class TestRandomAccessFile { public static void main(String[] args) throws IOException { //RandomAccessFile能随意定位到文件的具体位置 RandomAccessFile r = new RandomAccessFile("./test.txt", "rw"); r.seek(2);//按字节位置进行seek,test.txt文件是8个字节,通过seek能访问到对应字节位置的字符 r.write("9".getBytes());//此处是直接覆盖掉第三个位置的数据 int temp = -1; while ((temp = r.read())!=-1){//由于read方法会向后按照字节读取,因此从第4个位置开始读取 System.out.println("temp = " + ((char) temp)); } } }- 首先通过seek将位置移动到第三个位置,然后write替换掉原来数据,此时文件内容会由原来的
12345678变成12945678
- 首先通过seek将位置移动到第三个位置,然后write替换掉原来数据,此时文件内容会由原来的
- RandomAccessFile与nio(new io)结合使用。将上面的例子改成插入操作,而不是覆盖,此时可以用到nio中的FileChannel。RandomAccessFile的FileChannel,让你使用 NIO(New I/O)高速文件通道,让你能对文件进行更快、更底层的操作,然后通过map方法将file内容映射到内存,从而不像普通io一样read/write那样系统调用,不需要用户态内核态拷贝,返回的MappedByteBuffer 是内存映射文件,对 ByteBuffer 的操作就是在直接修改文件内容。比如下面通过put方法给指定位置插入字符的事例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32public class TestRandomAccessFile1 { public static void main(String[] args) throws IOException { int insertPos = 3; byte value = (byte) '9'; RandomAccessFile raf = new RandomAccessFile("./test.txt", "rw"); FileChannel channel = raf.getChannel(); long oldLen = channel.size(); long newLen = oldLen + 1; // 1. 扩展文件长度 raf.setLength(newLen); // 2. 重新 map 全文件区域 MappedByteBuffer buffer = channel.map( FileChannel.MapMode.READ_WRITE, 0, newLen ); // 3. 从后往前移动数据(避免覆盖) for (long i = oldLen - 1; i >= insertPos; i--) { byte b = buffer.get((int) i); buffer.put((int) (i + 1), b); } // 4. 插入新的字节 buffer.put(insertPos, value); channel.close(); raf.close(); } }- 上面操作完后,文件内容由原来的
12345678变成了123945678。
- 上面操作完后,文件内容由原来的
图片的字节读取
- 首先将图片转化成ByteBuffer数据:
|
|
获取RandomAccessFile的FileChannel,让你使用 NIO(New I/O)高速文件通道,让你能对文件进行更快、更底层的操作,然后通过map方法将file内容映射到内存,从而不像普通io一样read/write那样系统调用,不需要用户态内核态拷贝,返回的MappedByteBuffer 是内存映射文件,对 ByteBuffer 的操作就是在直接修改文件内容。
图片字节数据解析
获取到图片的字节数据后,接着就可以解析图片的格式、旋转角度等信息。
-
图片格式
- 首先读取到ByteBuffer数据
- 然后按照字节数量进行读取
- 如果前两个字节等于0xFFD8,则是JPEG格式
- 如果前四个字节等于0x89504E47,则是PNG格式
- 接着在PNG里面判断是否带透明格式
- 透明度是读取第25个字节数据,如果数值大于等于3,则说明是PNG带透明度的图片,否则就不带透明度的PNG图片。
- 接着判断是不是webp格式,webp图片是RIFF容器格式,它是由RIFF+文件大小+WEBP+VP8(有损)/VP8L无损/VP8X(扩展,支持 alpha / animation / ICC)
偏移 ASCII 16进制 含义 0x00 RIFF 52 49 46 46 RIFF标识 0x04 size xx xx xx xx 文件大小 - 8(小端) 0x08 WEBP 57 45 42 50 WebP 标识 8. VP8(有损WebP) - Chunk头(8字节)
偏移 ASCII 16进制 含义 0x00 VP8 56 50 38 20 VP8 标识 0x04 size xx xx xx xx 文件大小 - 8(小端) - VP8L(无损WebP)
- Chunk头(8字节)
偏移 ASCII 16进制 含义 0x00 VP8 56 50 38 4C VP8 标识 0x04 size xx xx xx xx 文件大小 - 8(小端)
- Chunk头(8字节)
- VP8X(扩展)
- Chunk头(8字节)
偏移 ASCII 16进制 含义 0x00 VP8 56 50 38 58 VP8 标识 0x04 size xx xx xx xx 文件大小 - 8(小端)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154public class TestRandomAccessFile2 { static final int EXIF_MAGIC_NUMBER = 0xFFD8; private static final int PNG_HEADER = 0x89504E47; private static final int GIF_HEADER = 0x474946; // WebP-related // "RIFF" private static final int RIFF_HEADER = 0x52494646; // "WEBP" private static final int WEBP_HEADER = 0x57454250; // "VP8" null. private static final int VP8_HEADER = 0x56503800; private static final int VP8_HEADER_MASK = 0xFFFFFF00; private static final int VP8_HEADER_TYPE_MASK = 0x000000FF; // 'X' private static final int VP8_HEADER_TYPE_EXTENDED = 0x00000058; // 'L' private static final int VP8_HEADER_TYPE_LOSSLESS = 0x0000004C; private static final int WEBP_EXTENDED_ANIMATION_FLAG = 1 << 1; private static final int WEBP_EXTENDED_ALPHA_FLAG = 1 << 4; private static final int WEBP_LOSSLESS_ALPHA_FLAG = 1 << 3; public static void main(String[] args) throws Exception { RandomAccessFile raf = new RandomAccessFile("./test.png", "rw"); FileChannel channel = raf.getChannel(); // 2. 重新 map 全文件区域 MappedByteBuffer buffer = channel.map( FileChannel.MapMode.READ_ONLY, 0, raf.length() ); buffer.order(ByteOrder.BIG_ENDIAN); ByteBuffer dup = buffer.duplicate(); dup.position(0);// 从头读 byte[] data = new byte[dup.remaining()]; dup.get(data); int i=0; //这个就是遍历全部的byte数据 for (byte datum : data) { int mdata = (datum& 0xFF); System.out.println((i++)+"mdata = " + Integer.toHexString(mdata));//16进制数转成10进制的字符串 } //读取前两个字节的数据 int firstTwoBytes = getUInt16(buffer); System.out.println("firstTwoBytes = " + Integer.toHexString(firstTwoBytes)); //如果前两个byte等于0xFFD8,则说明是JPEG格式 if (firstTwoBytes == EXIF_MAGIC_NUMBER) { System.out.println("当前图片是JPEG"); } //前两个byte数左移8位,然后再读取一个8位进行或运算就得到了前3个字节的16进制数据 final int firstThreeBytes = (firstTwoBytes << 8) | getUInt8(buffer); //如果前三个字节的数据等于0x474946,则说明是GIF格式 if (firstThreeBytes == GIF_HEADER) { return GIF; } //同理前3个字节的数据再读取到一个8位进行或运算得到前4个字节的16进制数据 final int firstFourBytes = (firstThreeBytes << 8) | getUInt8(buffer); //如果前4个字节的数据等于0x89504E47,则说明是PNG类型 if (firstFourBytes == PNG_HEADER) { // See: http://stackoverflow.com/questions/2057923/how-to-check-a-png-for-grayscale-alpha // -color-type //第25位读取透明度信息,由于前面已经读取了4位,因此减去4 skip(buffer, 25 - 4); try { //然后读取到第25位的字节素具 int alpha = getUInt8(buffer); System.out.println("alpha = " + Integer.toHexString(alpha)); // A RGB indexed PNG can also have transparency. Better safe than sorry! //如果大于等于3则说明带透明度信息 if (alpha >= 3) { System.out.println("当前图片是带透明的PNG图片"); } else { System.out.println("当前图片是不带透明的PNG图片"); } } catch (Exception e) { // TODO(b/143917798): Re-enable this logging when dependent tests are fixed. // if (Log.isLoggable(TAG, Log.ERROR)) { // Log.e(TAG, "Unexpected EOF, assuming no alpha", e); // } System.out.println("异常:当前图片是不带透明的PNG图片"); } } //webp图片格式读取,首先读取RIFF标识,如果不是则按照AVIF格式读取 if (firstFourBytes != RIFF_HEADER) { // Check for AVIF (reads up to 32 bytes). If it is a valid AVIF stream, then the // firstFourBytes will be the size of the FTYP box. return sniffAvif(reader, /* boxSize= */ firstFourBytes); } // WebP (reads up to 21 bytes). // See https://developers.google.com/speed/webp/docs/riff_container for details. // Bytes 4 - 7 contain length information. Skip these. //偏移四位,把size的4个字节给跳过 reader.skip(4); //第三个4字节,也就是WebP标识 final int thirdFourBytes = (reader.getUInt16() << 16) | reader.getUInt16(); //判断第三个4字节是不是0x57454250 if (thirdFourBytes != WEBP_HEADER) { return UNKNOWN; } //第4个4字节 final int fourthFourBytes = (reader.getUInt16() << 16) | reader.getUInt16(); //判断有没有VP8块,这里抹掉了最低byte数,因为高3位都是一样的,不需要比较最低一位 if ((fourthFourBytes & VP8_HEADER_MASK) != VP8_HEADER) { return UNKNOWN; } //判断最低一个字节是不是16进制的58,也就是是不是VP8X if ((fourthFourBytes & VP8_HEADER_TYPE_MASK) == VP8_HEADER_TYPE_EXTENDED) { // Skip some more length bytes and check for transparency/alpha flag. //跳过size的4位 reader.skip(4); //获取到flag位占一个byte short flags = reader.getUInt8(); //如果flag等于2,则是带Animation if ((flags & WEBP_EXTENDED_ANIMATION_FLAG) != 0) { return ANIMATED_WEBP; } else if ((flags & WEBP_EXTENDED_ALPHA_FLAG) != 0) {//判断flag等于16,也就是带alpha return ImageType.WEBP_A; } else { return ImageType.WEBP;//否则是普通的 } } //判断最低一个字节是不是16进制的4C,也就是是不是VP8L if ((fourthFourBytes & VP8_HEADER_TYPE_MASK) == VP8_HEADER_TYPE_LOSSLESS) { // See chromium.googlesource.com/webm/libwebp/+/master/doc/webp-lossless-bitstream-spec.txt // for more info. //跳过size占用的4字节位置 reader.skip(4); //读取flag标志 short flags = reader.getUInt8(); //判断flag是否等于8,也就是是不是带alpha return (flags & WEBP_LOSSLESS_ALPHA_FLAG) != 0 ? ImageType.WEBP_A : ImageType.WEBP; } //最后用webp格式兜底 return ImageType.WEBP; channel.close(); raf.close(); } private static short getUInt8(ByteBuffer buffer) throws Exception { return (short) (buffer.get() & 0xFF); } private static int getUInt16(ByteBuffer buffer) throws Exception { return ((int) getUInt8(buffer) << 8) | getUInt8(buffer); } private static long skip(ByteBuffer byteBuffer, long total) { int toSkip = (int) Math.min(byteBuffer.remaining(), total); System.out.println("skip:"+(byteBuffer.position() + toSkip)); byteBuffer.position(byteBuffer.position() + toSkip); return toSkip; } }